Texts written in natural language are generally unstructured, meaning that they are not organized in a pre-defined structure, such as a table. Rather, writers often mean to tell a story, and let their text flow freely in sentences and paragraphs. While such texts typically are more fun to read, the information they contain is not as readily available.
This blog presents a tutorial in Named Entity Recognition (NER), which is the task of automatically extracting information from unstructured texts. Specifically, that information concerns ‘named entities’, such as people, locations, events, or dates. In this blog, we will extract dates from biographies, and chronologically present these dates and their associated events in a table.
We will be working with biographical texts from www.biography.com, by the example of a text on German politician Angela Merkel.

Picture taken from https://www.biography.com/people/angela-merkel-9406424
The data
I’m assuming that you already have the raw text saved in a text file (download the Merkel example here), and have removed the irrelevant parts of the biography, such as “Access Date: January 3, 2018”. If I have time, I might make the scraping and pre-processing part explicit in another blog later.
Your text file should look something like this (source):
Angela Merkel is a German politician best known as the first female chancellor of Germany and one of the architects of the European Union. Who Is Angela Merkel? […] “We expected a better result, that is clear,” Merkel said following the election. “The good thing is that we will definitely lead the next government.” She also said she would address supporters of the AfD “by solving problems, by taking up their worries, partly also their fears, but above all by good politics.
Setting up the text for date extraction
We will begin with the obvious: importing the relevant modules, setting the working directory, and opening the text file that contains the biography:
# Import modules
import os
import re
from nltk.tokenize import sent_tokenize
from texttable import Texttable
# Set working directory
os.chdir('C:/...')
# Open file
def open_file():
with open ('Angela Merkel.txt', encoding = 'utf-8') as file:
raw_text = file.read()
return raw_text
The text still needs some preprocessing. To begin with, we remove so-called ‘soft hyphens‘: invisible markers that are placed within words to indicate where they can potentially be broken off in order to span two lines. We also replace double newlines by a single newline. This will later be needed for sentence tokenization.
# Preprocess the text
def preprocess_text(text):
text = text.replace(chr(0x00AD), "") # Remove soft hyphens
text = text.replace("\n\n", "\n") # Remove spurious white lines
return text
Then, we use the sentence tokenizer from the Natural Language Toolkit to split the biography into a list of sentences.
The text still contains newline escape sequences (“\n”) after the paragraph headings. These are needed to signal that something is a heading, because the headings do not end in a period or another punctuation mark. However, the sent_tokenize function does not recognize “\n” as a place to split. Therefore, we manually split the biography at these points. This results in a list of lists, which we again unpack to return a simple list of sentences.
# Split text into sentences
def sent_splitter(text):
sents = sent_tokenize(text)
# Manually separate headings, because sent_tokenize does not split after '\n'
sents2 = [i.split("\n") for i in sents]
sents = [item for sublist in sents2 for item in sublist]
return sents
Using regular expressions to extract dates
Now that our text is read, cleaned and split, we come to the interesting part: extracting the dates. This is done by means of a regular expression (regex): a way to describe regularities in a text in terms of characters, digits or punctuation. For example, a four-digit year can be described as \d{4}. If you want to learn more about regular expressions, there are many tutorials available on YouTube.
We begin with creating an empty list to store the dates we will extract with the regex, and we define a list that contains the months of the year (this will be needed later).
Dates can be written in many formats. For example, there is “5 January 2018”, or “5th of January, 2018″, or even “05/01/2018” and “05-01-2018”, and so forth. Luckily, it seems that www.biography.com does not use the latter two notations, and neither abbreviates month names (e.g., “Jan”). This means our regex can be relatively simple. However, keep in mind that you might have to expand it when your text does use alternative date formats.
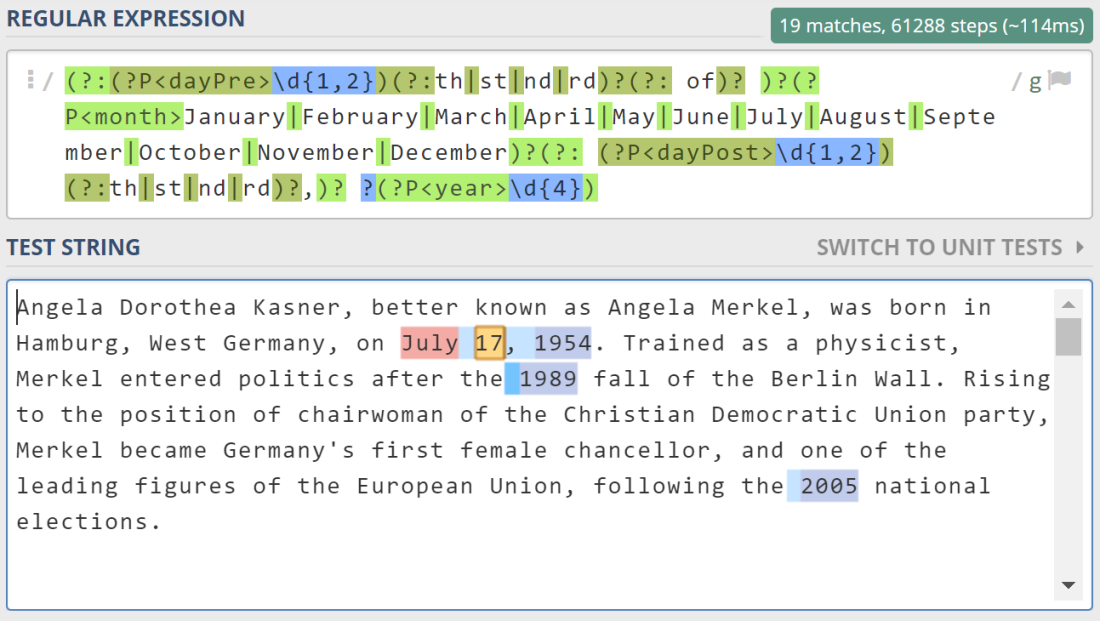
Then, we will loop through the sentences to find the dates. The full regular expression for matching dates is:
# Extract dates from text with a regular expression
def extract_dates(sents):
bio = []
months = ["January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December"]
for sent in sents:
matches = re.finditer(r"(?:(?P\d{1,2})(?:th|st|nd|rd)?(?: of)? )?"
"(?PJanuary|February|March|April|May|June"
"|July|August|September|October|November|December)?"
"(?: (?P\d{1,2})(?:th|st|nd|rd)?,)? ?"
"(?P\d{4})", sent)
# (This function will continue below)
Let’s take it apart. The regex starts after “r”. The first row in the regex is meant for matching dates where the day precedes the month (e.g., “5 January”). It looks for 1 or 2 digits, optionally followed by “th”, “st”, “nd” or “rd”, optionally followed by “of”. Thus, it will match strings such as “5”, “31st”, and “22nd of”. Only the digit part of this string (e.g., “5”, “31”, “22” will be saved under the name “dayPre”).
The second row will match any of the twelve months, and store it under the name ‘month’. Luckily for us, www.biography.com does not seem to abbreviate months (e.g., “Jan” for “January”) or write them as a number (“1” for “January”), so our simple list suffices. For other sources, you might have to also match abbreviations or numbers.
The third row is similar to the first one, but is used in case the day follows the months (e.g., “January 5th”). This format would not use the word “of”, so it is absent in the third row of the regex.
Finally, the year simply is matched as a sequence of four digits. This suffices for www.biography.com, but other sources might also use things like “’18”, and you would have to match that.
To try it out for yourself, copy the above regular expression (regex) into the text box at www.regex101.com. Remove all the quotes and newlines, so that the regex becomes one long string. Enter the biography in the text box below (you can add extra dates to play around with).
Putting the information together in a nice table
All of the dates have now been stored in matches. If we print matches, the output looks like this (the first element is always None in this case, because this biography consequently uses months before days):
(None, 'July', '17', '1954') (None, None, None, '1989') (None, None, None, '2005')
The next step is to append the empty bio list with tuples of dates and the events that happened on those dates. For example: (1954-7-17, “Angela Dorothea Kasner, better known as Angela Merkel, was born in Hamburg, West Germany, on July 17, 1954.”). We format the dates as year-month-day, because this enables chronological sorting.
# (This is the continuation of the above extract_dates function)
# Extract year, month and day from matches
for match in matches:
print(match.groups())
year = match.group('year')
date = year
# Months are optional
if match.group('month'):
month = match.group('month')
month = str(months.index(month)+1) # Express month as a digit (makes it easier to sort months)
date += "-" + month
# Days are also optional
if match.group('dayPre'):
day = match.group('dayPre')
date += "-" + day
elif match.group('dayPost'):
day = match.group('dayPost')
date += "-" + day
# Append the (date, sent) tuple to the biography list
bio.append((date, sent))
return bio
Now, define a function that sorts the tuples chronologically:
# Sort dates chronologically def sort_dates(bio): bio.sort(key=lambda x: x[0]) return bio
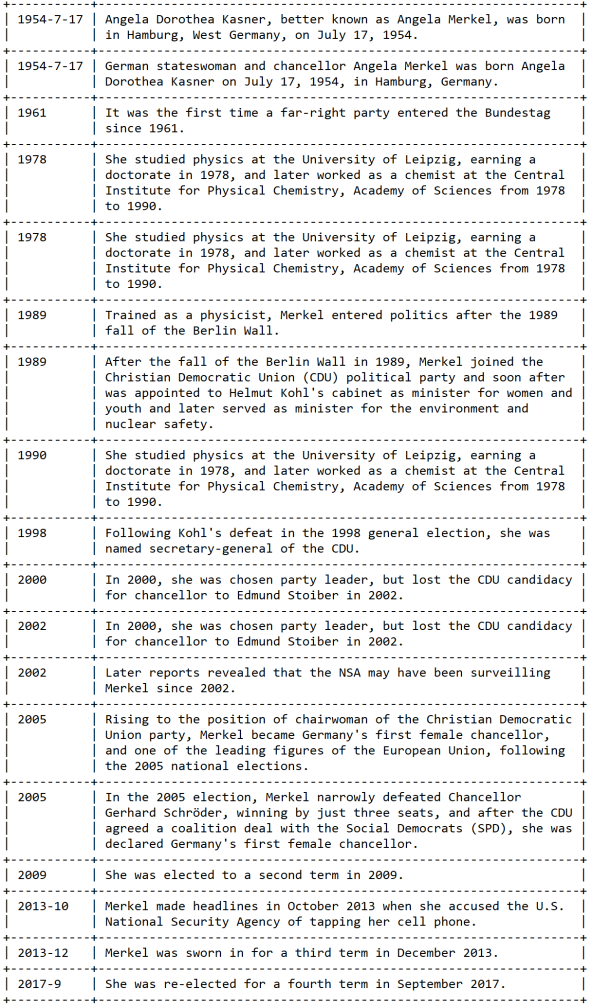
At this point, we have a sorted list of tuples:
[('1871', 'Merkel is also the first former citizen of the German Democratic Republic to lead the reunited Germany and the first woman to lead Germany since it became a modern nation-state in 1871.'),
('1954-7-17', 'Angela Dorothea Kasner, better known as Angela Merkel, was born in Hamburg, West Germany, on July 17, 1954.'),
[...]
('2013-12', 'Merkel was sworn in for a third term in December 2013.'),
('2017-9', 'She was re-elected for a fourth term in September 2017.')]
However, as you can see it is funny that Merkel’s biography starts with the year 1871, while she was actually born in 1954. Content-wise as well, it is not relevant to her biography. Therefore, we define a function that removes dates and events before the date of birth. We do so by checking when the string “born” first appears in the biography.
# Start the timeline with the year the person was born
def after_birth(bio_sorted):
while True:
for i in range(len(bio_sorted)):
if "born" in bio_sorted[i][1]:
index = i
break
break
bio_from_birth = bio_sorted[index:]
return bio_from_birth
With the following function, the list is printed as a pretty table:
# Make and print table def make_table(bio_sorted): bio_table = Texttable() for date, sent in bio_sorted: bio_table.add_row([date, sent]) print(bio_table.draw()) return bio_table
Finally, run the code:
# Run code if __name__ == "__main__": raw_text = open_file() prep_text = preprocess_text(raw_text) sents = sent_splitter(prep_text) bio = extract_dates(sents) bio_sorted = sort_dates(bio) bio_from_birth = after_birth(bio_sorted)
The results are printed below. As you can see, the same sentence can be printed multiple times if it contains more than one date. It is easy to change this and print each sentence only once, but this could interfere with chronological sorting if the dates within a sentence are far apart.
For now, let us just enjoy the nice and structured timeline we extracted from an unstructured text!
Want to try it yourself?
Download the Python code and Merkel example text here. You can also go to www.biography.com and save the biography of a person of your choice. If you use another biography from elsewhere, you may have to make some changes to the regular expression to also capture dates written in other formats.
